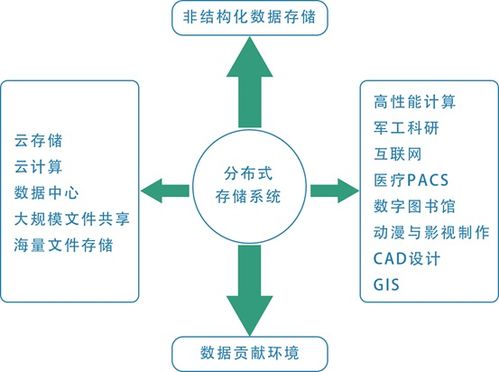
自服務治理 彌合用戶與大數據處理服務間的認知與應用鴻溝
在數據驅動決策的時代,用戶與大數據處理服務之間常存在一道顯著的鴻溝。一方面,業務人員需要數據洞察卻缺乏技術能力;另一方面,技術團隊深陷數據需求洪流,難以高效響應。自服務治理(Self-Service Governance)作為一種新興范式,正致力于消除這一隔閡,通過賦予用戶安全、可控的數據訪問與處理能力,實現數據價值的民主化與敏捷釋放。
一、鴻溝的根源:技術復雜性與業務需求的錯配
傳統大數據處理流程通常依賴專業數據團隊作為中間橋梁。業務用戶提出需求,數據工程師進行數據抽取、清洗、建模與分析,最終交付報表或洞察。此模式存在明顯瓶頸:
- 溝通成本高:業務語言與技術語言轉換易產生誤解,需求迭代周期長。
- 資源瓶頸:數據團隊精力有限,難以應對海量、碎片化的即時分析需求。
- 敏捷性不足:市場變化迅速,漫長的數據處理周期可能導致洞察滯后,商機貽誤。
二、自服務治理的核心內涵:賦能與管控的平衡
自服務治理并非簡單的“把工具交給用戶”,而是一套融合了技術平臺、管理策略與文化變革的體系。其核心目標是在降低使用門檻的確保數據的安全性、質量與合規性。
關鍵支柱包括:
1. 直觀的可視化交互界面:提供類似拖拽式的數據準備、可視化分析工具,讓業務用戶無需編寫復雜代碼即可探索數據、創建圖表與儀表盤。
2. 智能化的數據目錄與搜索:建立企業級數據資產地圖,通過業務術語(而非技術表名)對數據進行編目、描述和標記。用戶可像使用搜索引擎一樣,快速發現和理解所需數據。
3. 嵌入式的數據質量管理:在用戶使用數據的過程中,平臺自動提示數據的完整性、時效性及可信度,并提供數據血緣追溯功能,讓用戶知曉數據來源與加工過程。
4. 動態、精細化的訪問控制:基于角色、項目或數據敏感度的策略,自動執行數據訪問權限的審批與授予,確保“最小權限原則”,并全程記錄數據訪問行為以供審計。
5. 協作與知識共享環境:支持用戶將分析過程、圖表和洞察保存為可復用的模板或故事線,方便團隊內部分享與協作,沉淀數據分析最佳實踐。
三、實施路徑:從平臺建設到文化培育
成功部署自服務治理是一個系統性工程:
1. 技術平臺層:構建統一的數據門戶
整合數據存儲、計算引擎與各類分析工具,通過統一的API和服務層進行抽象,對外提供一致、友好的自服務入口。重點在于屏蔽底層技術復雜性。
2. 治理規則層:制定清晰的策略
與法務、合規及業務部門共同制定數據分類分級標準、訪問策略、使用規范和質量標準。這些規則應盡可能自動化地嵌入平臺流程中。
3. 運營支持層:提供持續的支持與培訓
設立“數據賦能中心”或“公民數據科學家”社區,為用戶提供培訓、最佳實踐指導和即時幫助。技術團隊角色從需求執行者轉變為平臺構建者、規則制定者和教練。
4. 文化變革層:倡導數據驅動的決策文化
領導層需率先垂范,鼓勵基于數據的探索與試錯。通過成功案例展示自服務帶來的效率提升與業務價值,激發全員參與數據應用的熱情。
四、收益與展望
通過自服務治理,企業能夠:
- 提升決策速度與敏捷性:業務用戶可即時驗證想法,縮短從問題到洞察的周期。
- 解放數據團隊生產力:使其專注于高價值的架構優化、模型開發與復雜問題解決。
- 深化數據應用廣度與深度:更多角色參與數據分析,可能催生意想不到的創新洞察。
- 降低合規與安全風險:通過系統化的治理,確保數據在可控范圍內被合規使用。
隨著自然語言處理、增強分析等AI技術的融合,自服務體驗將更加智能與自然。用戶僅需用業務語言提問,系統便能自動完成數據查找、處理與分析,真正實現數據與業務思維的無縫銜接。自服務治理將推動組織進化為一個真正“數據原生”的智能體,讓大數據處理服務如同水電一般,可靠、易用且賦能于每一位員工。
如若轉載,請注明出處:http://m.tusx.com.cn/product/62.html
更新時間:2026-01-07 16:27:56