掌握Azure數據工廠 構建高效云數據集成與數據處理解決方案
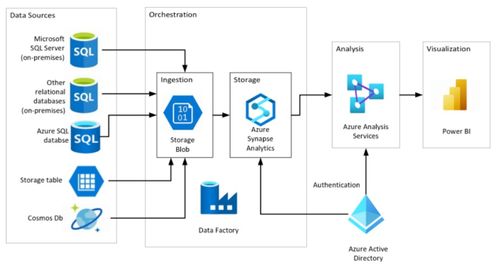
在當今數據驅動的商業環境中,企業面臨著海量、異構數據的高效整合與處理挑戰。Azure數據工廠(Azure Data Factory, ADF)作為微軟Azure云平臺提供的一項完全托管的云原生數據集成與編排服務,已成為構建現代化、可擴展數據管道的核心工具。掌握ADF,意味著能夠設計和實施端到端的云數據集成解決方案,實現數據從多樣化的源系統到目標存儲與分析平臺的自動化流動、轉換與加載。
一、Azure數據工廠的核心定位:云數據集成的中樞
Azure數據工廠本質上是一個無服務器(Serverless)的數據集成服務,它允許用戶創建、調度和編排復雜的數據工作流(稱為“管道”),而無需管理底層基礎設施。其核心價值在于:
- 混合與多云數據集成:輕松連接并移動位于本地(通過自承載集成運行時)、Azure云內(如Azure SQL Database, Blob Storage)以及其他云服務(如Amazon S3, Google Cloud Storage)中的數據。
- 代碼與低代碼并存:既支持通過可視化拖拽界面(UI)快速構建數據流,也允許開發者使用代碼(如JSON定義、數據流腳本)進行更精細的控制和自動化部署。
- 編排與調度:作為數據管道的“指揮家”,它能以時間(如每日、每小時)或事件(如新文件到達)為觸發器,協調一系列數據活動(復制、轉換、外部作業執行)的執行順序和依賴關系。
二、構建云數據集成解決方案的關鍵組件
一個典型的ADF解決方案由以下幾個關鍵組件構成:
- 鏈接服務(Linked Service):相當于數據源的“連接字符串”定義器。它存儲了連接到外部數據存儲(如Azure SQL數據庫、SFTP服務器)或計算資源(如Azure HDInsight集群、Azure Databricks)所需的連接信息。這是所有數據活動的基礎。
- 數據集(Dataset):定義了在鏈接服務所指向的存儲中,待處理數據的結構和格式。它指向特定的表、文件、文件夾或文件模式,為后續的復制和轉換操作提供輸入和輸出的數據視圖。
- 管道(Pipeline):解決方案的邏輯容器和最高層組織單元。一個管道代表一個完整的業務工作流,由一系列按順序或并行執行的活動(Activity)組成。
- 活動(Activity):管道中的基本執行單元。ADF提供了豐富的活動類型:
- 數據移動活動:如“復制活動”,用于在不同數據存儲間高效復制數據。
- 數據轉換活動:如“映射數據流活動”,提供基于Spark的、可視化的無代碼/低代碼數據轉換體驗;或“執行SSIS包活動”,用于遷移和運行傳統的SQL Server Integration Services包。
- 控制流活動:如“If Condition”、“ForEach”、“Until”等,用于實現復雜的流程控制邏輯。
- 外部執行活動:如“存儲過程活動”、“自定義活動”(運行自定義代碼)、“Web活動”(調用REST端點)等,用于擴展管道能力。
- 觸發器(Trigger):決定管道何時運行。支持計劃觸發器(按固定頻率)、事件觸發器(響應如Blob創建等事件)和翻轉窗口觸發器(處理基于時間窗口的數據)。
- 集成運行時(Integration Runtime, IR):ADF的計算基礎設施,負責執行數據移動、調度活動和分發轉換任務。主要分為:
- Azure IR:全托管,用于云內數據操作。
- 自承載IR:安裝在本地或虛擬網絡中,用于訪問私有網絡中的數據源。
- Azure-SSIS IR:專門用于運行SSIS包。
三、利用ADF構建端到端數據處理服務
一個完整的云數據處理服務通常遵循 ELT/ETL 模式:提取(Extract)、加載(Load)、轉換(Transform)。ADF在此過程中扮演關鍵角色:
- 數據提取與引入:使用“復制活動”從各種操作型系統、SaaS應用、IoT設備、日志文件等源頭,將原始數據高效、可靠地引入到Azure的“數據湖”(如Azure Data Lake Storage Gen2)或“數據倉庫暫存區”(如Azure Synapse Analytics專用SQL池)。此階段側重于數據的移動和初步的格式統一。
- 數據轉換與豐富:在數據加載到中央存儲后,利用“映射數據流活動”進行大規模、可視化的數據轉換。這包括數據清洗(處理缺失值、異常值)、標準化、聚合、連接(Join)、列派生、數據脫敏等。映射數據流在后臺編譯為Spark作業,在無服務器Spark集群上執行,具備強大的伸縮能力。對于更復雜的業務邏輯,可以調用Azure Databricks筆記本或Azure Synapse Spark池進行高級分析。
- 數據加載與交付:將清洗和轉換后的數據,加載到目標分析存儲中,如Azure Synapse Analytics、Azure SQL Database或Azure Analysis Services,供Power BI等工具進行可視化分析和報表生成。ADF管道確保數據以正確的格式和頻率更新。
- 編排、監控與運維:ADF管道將上述步驟串聯成一個自動化的工作流。通過內置的監控界面(Azure門戶)、日志和指標,可以清晰地追蹤每次管道運行的詳細信息、持續時間、數據量以及成功/失敗狀態。結合Azure Monitor和警報,可以實現對數據管道的主動運維和故障快速響應。
四、最佳實踐與考量
- 安全性:盡可能使用Azure Key Vault管理連接字符串和密碼等機密信息。利用托管身份(Managed Identity)進行Azure資源間的安全身份驗證。通過VNet服務終結點和私有終結點保護數據訪問。
- 性能與成本優化:針對“復制活動”,合理設置數據集成單元(DIU)和并行度。對于“映射數據流”,根據數據量和轉換復雜度選擇適當的計算類型和核心數。利用管道參數化實現配置的動態化和復用。
- 錯誤處理與魯棒性:在管道設計中加入重試策略、超時設置以及失敗后的自定義處理邏輯(如發送警報郵件、記錄錯誤日志),確保數據管道的可靠性。
- DevOps與CI/CD:將ADF資源(管道、數據集等)的JSON定義存儲在Git倉庫中,利用Azure DevOps或GitHub Actions實現自動化測試和部署,提升開發和運維效率。
結論
Azure數據工廠是構建現代化、彈性、可管理云數據集成與處理解決方案的基石。通過掌握其核心概念、組件和工作原理,數據工程師和架構師能夠設計出自動化、可擴展的數據流水線,將原始數據高效轉化為可供分析和決策的可靠信息資產,從而賦能企業的數據驅動文化,加速數字化轉型進程。從簡單的數據移動到復雜的大數據轉換編排,ADF提供了一個統一且強大的平臺來應對日益增長的數據集成挑戰。
如若轉載,請注明出處:http://m.tusx.com.cn/product/57.html
更新時間:2026-01-07 07:42:19